Evaluators
Overview
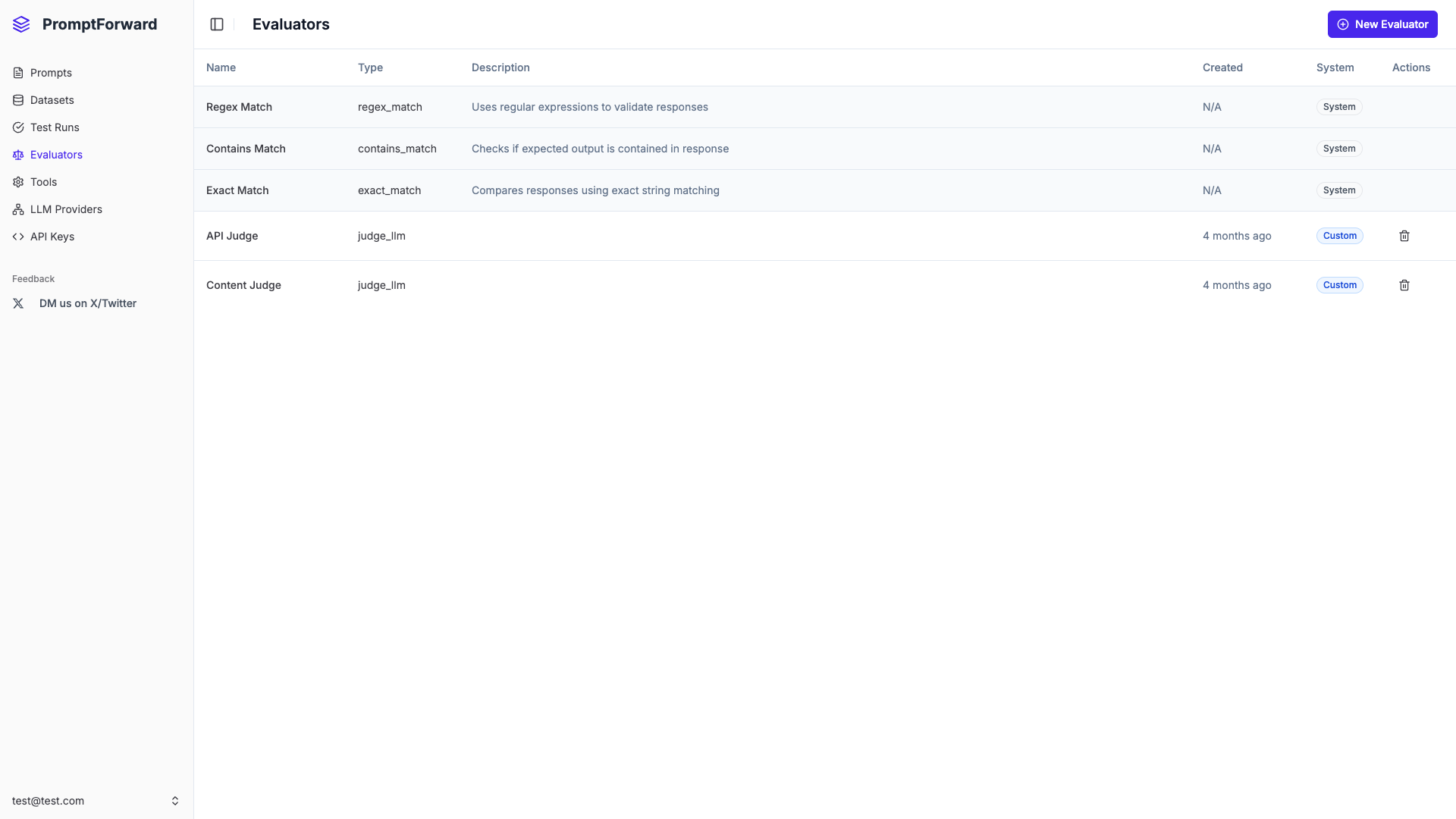
Evaluators are automated quality assessment tools that score and validate AI-generated outputs against your quality standards. They can use exact matching, pattern matching, or AI-powered judging.
Evaluator Types
System Evaluators
- Exact Match - Compares outputs character-for-character
- Contains Match - Checks if expected text appears in output
- Regex Match - Validates using regular expressions
Custom Evaluators
- Judge LLM - Uses an AI model to assess quality based on custom criteria
- Regex Match - Custom regex patterns for your specific validation needs
Creating a Judge LLM Evaluator
- Click New Evaluator
- Enter a descriptive name
- Select Judge LLM as the type
- Select an LLM Provider
- Choose a model (consider cost-effective models like gpt-4o-mini)
- Select an Evaluation Prompt (must have LLM Judge flag enabled)
- Click Create Evaluator
Testing an Evaluator
- Navigate to the evaluator's detail page
- Scroll to the Testing section
- Enter sample text in Actual Output
- Enter Expected Output (if required)
- Click Test
- Review the score and reasoning
Using Evaluators
In Test Runs
- Create a new test run
- Click Add Evaluator
- Select the evaluator
- Specify the output column from your dataset
- Add additional evaluators if needed
In API Inference
Include evaluator IDs in your API request:
{
"messages": [...],
"evaluators": ["evaluator-id-1", "evaluator-id-2"]
}Best Practices
- Start with system evaluators before creating custom ones
- Use cost-effective models for Judge LLM evaluators
- Test before deploying to production
- Create focused judge prompts with clear criteria
- Combine multiple evaluators for comprehensive assessment
- Name descriptively